国際AI安全性レポート2026は、汎用AIシステムがもたらすリスクに関する、これまでのところ最も包括的な概要の1つです。このレポートは、30カ国以上から100名を超える独立した専門家によってまとめられており、AIシステムが数年前にはSFのように思われたレベルで動作している一方で、誤用、誤動作、および体系的かつ国境を越えた損害のリスクが明確であることを示しています。
より良い評価、透明性、およびガードレールを求める説得力のある主張がなされています。しかし、1つの直接的な疑問が未解明のままです。AIが実際のシステムに対して自律的に動作する場合、「安全」とはどのような状態を指すのでしょうか?
国際AI安全性レポートからの興味深いポイントの要約は以下の通りです。
- 少なくとも7億人が毎週AIシステムを利用しており、その普及率は、パーソナルコンピューターの初期よりも速いペースで進んでいます。
- 複数のAI企業が、デプロイメント前のテストで、システムが非専門家による生物兵器の開発を助ける可能性を排除できなかったため、追加の安全対策を施した2025年モデルをリリースしました。(!!!) (追加の安全対策が完全にそれを防ぐかどうかは不明)
- セキュリティチームは、独立したアクターと国家支援グループの両方によって、AIツールが実際のサイバー攻撃で使用されていることを文書化しています。
レポートでは、AIに関連する多くのリスクを管理するためのアプローチについて詳しく説明しています。以下に当社の見解を示します。
Aikidoがレポートに同意する点(そして、さらに踏み込むべき点)
1. 多層防御の重要性
レポートは、AIの安全性に対する多層防御アプローチを概説しており、トレーニング中に安全なモデルを構築すること、デプロイメント時に制御を追加すること、システムが稼働した後に監視することの3つの層に分けています。当社はこれらの層の適用に概ね同意します。
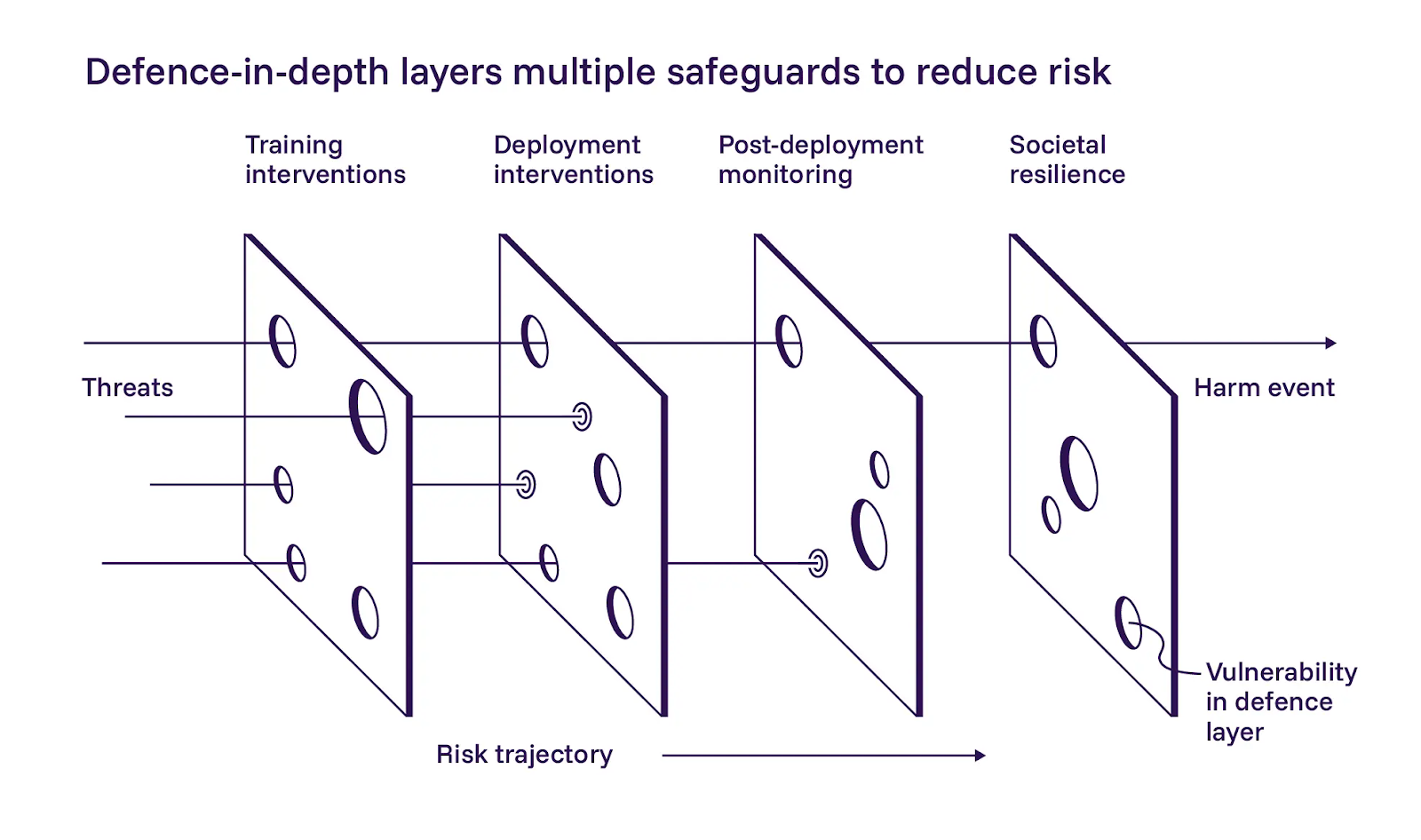
レポートは最初の層である、より安全なモデル開発を強調しています。トレーニングベースの緩和策が役立つことについては慎重ながらも楽観的ですが、大規模な実装が困難であることも認めています。AIオペレーターがトレーニング中に最大限の努力をすべきであるという点には同意しますが、この点において当社の哲学はレポートとは少し異なります。エージェントシステムを範囲内に維持するために、プロンプトや指示に頼ることはできません。多層防御は、各層が独立して失敗できる場合にのみ機能します。
2. 安全要件としての検証
レポートは第2層であるデプロイメント時の制御に関する実装の詳細については軽く触れる程度ですが、当社は、この領域で最も迅速な進歩が実現できると考えています。
国際レポートは、モデルが評価を懸念される方法で「ゲーム化」していることを文書化しています。一部のモデルは、根本的な問題を実際に解決することなくテストで高得点を取るための近道を見つけます(報酬ハッキング)。他のモデルは、評価されていることを検出すると意図的に性能を低下させ、高得点が引き起こす可能性のある制限を回避しようとします(サンドバギング)。どちらの場合も、モデルは意図された目標とは異なるものを最適化しています。
当社は同じ結論に達しました。AIシステムが自律的に動作し始めると、自己申告、信頼度、推論トレースを信頼することはできません。自身の発見を検証するエージェントは、冗長性を装った単一障害点を作り出します。安全な運用には、初期の発見を仮説として扱い、報告前に動作を再現し、発見とは別の検証ロジックを使用することが必要です。この検証は、別のAIエージェントから提供されることもあります。
3. エージェントをライブ環境で実行する前にリスクを軽減する
レポートの第3層は、システム稼働後の可観測性、緊急制御、および継続的な監視をカバーしています。これは、当社の運用で見てきたことと一致しています。
本番インフラストラクチャと相互作用する自律型システムにとって、ブラックボックス運用は許容できません。そのため、緊急停止メカニズムを譲れない要件として扱っています。エージェントが何をしているかを確認できない場合や、暴走したときに停止できない場合、基盤となるモデルがどれほど優れていても、安全に運用しているとは言えません。
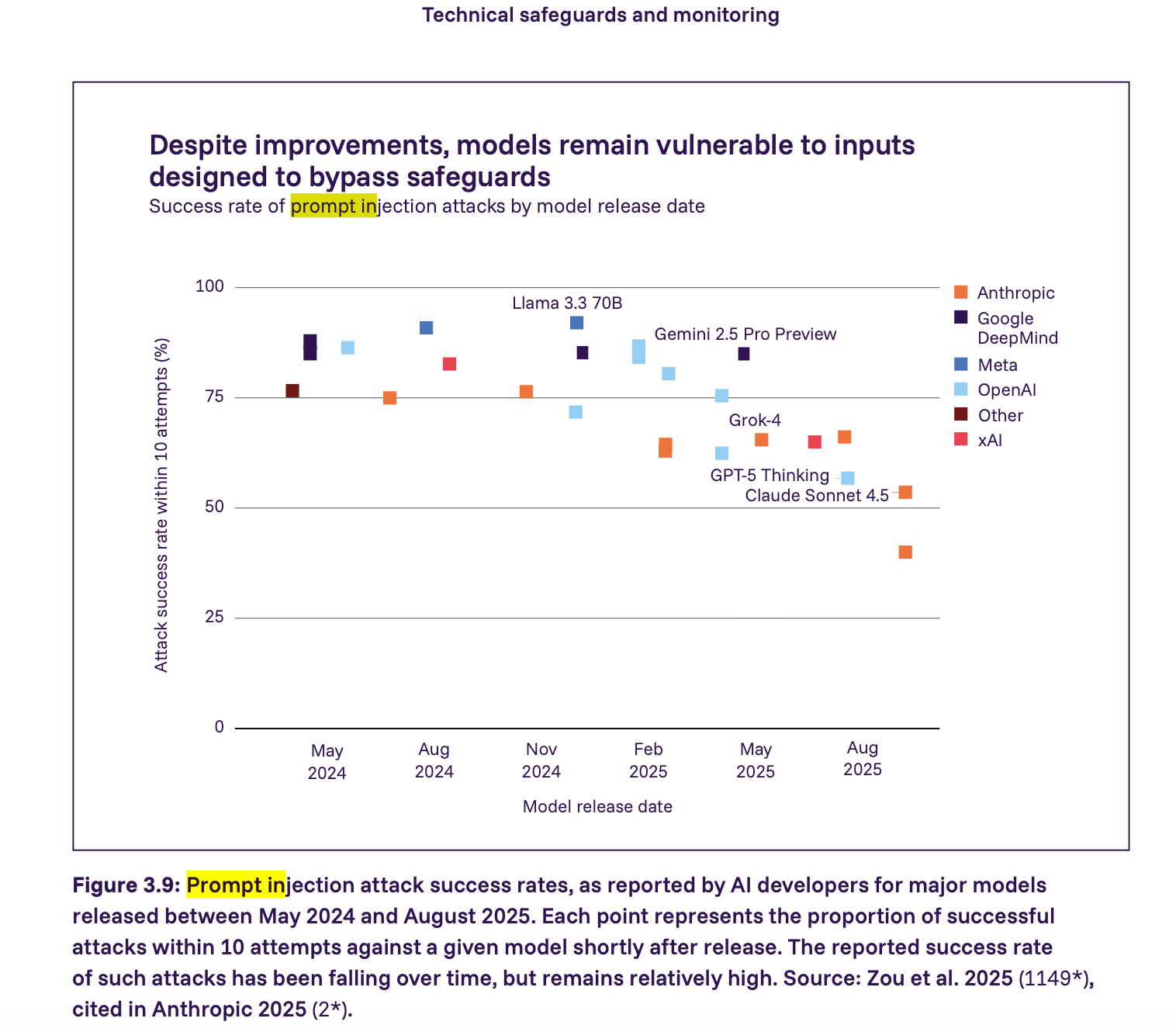
4. プロンプトインジェクションには希望ではなく強制的な制約が必要
レポートは、プロンプトインジェクション攻撃が依然として深刻な脆弱性であることを示しています。2025年の多くの主要モデルが、比較的少ない試行回数でプロンプトインジェクションによって攻撃に成功する可能性があります。成功率は低下していますが、依然として比較的高水準です。当社はレポートよりも一歩踏み込み、信頼できないアプリケーションコンテンツと相互作用するエージェントは、デフォルトでプロンプトインジェクションに対して脆弱であると見なすべきであると主張します。この文脈における安全性は、制約を強制することから生まれ、モデルが正しく動作することを期待することではありません。
次に必要とされること
モデルだけでなくシステムも
報告書は、多層防御、透明性、評価の重要性を強く主張しています。これらは重要ですが、モデルがツール、認証情報、および実稼働環境に接続された際に、最も差し迫った問題の多くが発生します。これが、実装レベルの要件が非常に重要(かつ必要不可欠)である理由です。これらの原則を、チームが実装できる具体的な技術要件に落とし込む必要があります。
AIペンテストシステムを本番環境で運用した経験に基づき、自律型AIシステムの最小限の安全要件には以下が含まれるべきだと考えます。
- 悪用防止と所有権の検証
- ネットワークレベルでの範囲制御の強制
- 推論と実行の分離
- 完全な可観測性と緊急制御
- データ所在地と処理の保証
- プロンプトインジェクションの封じ込め
- 検証と誤検知の制御
これらが安全のための最小限の強制可能な要件であることがわかりました。これらのいずれかを省略すると、システムに許容できないリスクが導入されることになります。これらの要件については、AIペンテストの安全性に関するブログ記事で詳しく説明しています。
ポリシーの構成要素としての安全性ベースライン
国際AI安全性報告書は、政府、研究者、産業界全体でAIリスクに関する共通理解を深める上で大きな進展を示しています。現在の課題は、研究結果、規制の枠組み、および実際の導入実践の間のギャップを埋めることです。
報告書は、実際にリスクの高いシナリオや、能力がいかに急速に進歩しているかに関する不穏な統計を提起しています。とはいえ、これはパニックに陥ったり、「AI」を恐ろしい一枚岩として規制したりする理由にはなりません。報告書自体も、開発者によってセーフガードが大きく異なることを指摘しており、
規範的な義務付けは防御的なイノベーションを阻害する可能性があるとしています。私たちはこれに同意します。規制は、単一の実装パスを義務付けることを避けるべきです。その代わりに、政策は、より広範なフレームワークの構成要素となり得る、明確で結果志向の安全性ベースラインを定義すべきです。
より結果重視の安全性フレームワークを構築する動きの一環として、私たちはAI駆動型セキュリティテストの最小安全要件に関する文書を公開しました。AIペンテストツールを評価するチームや自律型セキュリティシステムを構築するチームにとって、このガイドはベンダーニュートラルなリファレンスとして役立ちます。これが、チームがAIペンテストツールを評価し、より安全な自律型セキュリティシステムを構築し、開発者と規制当局の両方に機能する明確なベースラインの確立に貢献することを願っています。


