はじめに
適切なコードセキュリティツールを選択することは、開発セキュリティ戦略の成否を左右します。SnykとSemgrepは、脆弱性を早期に発見するための開発者中心のアプローチでよく比較されます。どちらもセキュリティチェックを開発に統合することで、チームがより安全なコードを出荷するのに役立ちますが、それぞれ異なる焦点を持ちます。この比較では、両者がどのように優れているか、そしてセキュアなソフトウェアデリバリーを担当する技術リーダーにとって、その選択がなぜ重要であるかを探ります。
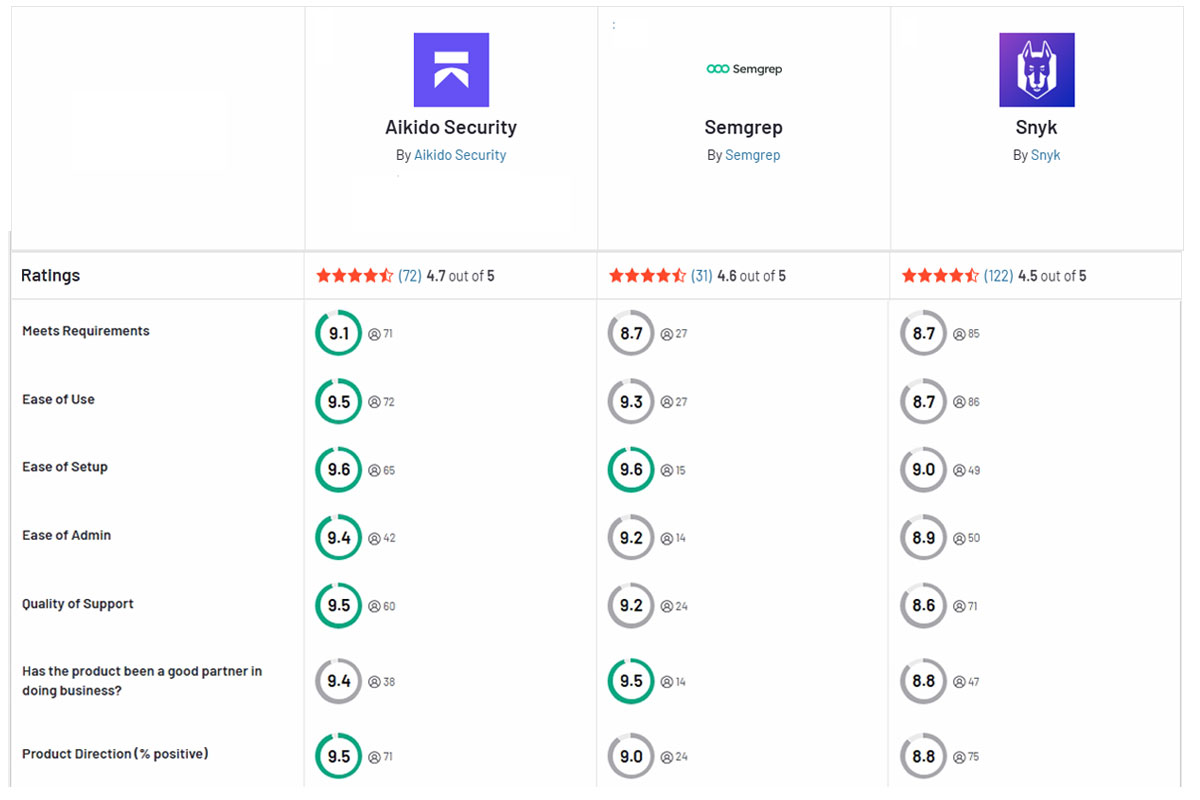
要約
SnykとSemgrepはどちらもコードベースのセキュリティ強化に役立ちますが、それぞれ異なるレイヤーに焦点を当てており、両方に盲点があります。Snykはオープンソースの依存関係とコンテナのスキャンに優れており、一方Semgrepは静的コード分析を専門としています。Aikido Securityは、はるかに少ない誤検知とシンプルな統合により、両方の世界を1つのプラットフォームに統合し、現代のセキュリティチームにとってより良い選択肢となっています。
SnykとSemgrepの概要
Snyk
Snykは、オープンソースライブラリやその他のコンポーネントにおける脆弱性の発見で知られる開発者ファーストのセキュリティプラットフォームです。ソフトウェア構成分析 (SCA)から始まり、脆弱な依存関係を捕捉しましたが、その後、コンテナイメージ、Infrastructure-as-Code、さらにはSnyk Codeを介した静的コードのスキャンにまで拡大しました。Snykの強みは、開発ワークフロー(GitHub、CI/CDパイプライン、IDEなど)にシームレスに組み込まれ、開発者にリスクを早期に警告することです。“シフトレフト”セキュリティを重視しており、アジャイルなDevOpsチームの間で人気があります。しかし、Snykの広範なアプローチには、深度とノイズに関するトレードオフがあり、これについては後述します。
Semgrep
Semgrepは、ソースコードのバグやセキュリティ問題をスキャンすることに特化したオープンソースの静的解析(SAST)ツールです。柔軟なルールベースのパターンマッチングを使用して、セキュリティ脆弱性からコード品質のミスまであらゆるものを検出します。Semgrepは軽量で言語を認識し、複雑な設定なしでCIパイプラインで高速に実行できます。その主な魅力はカスタマイズ性です。チームはYAMLで独自のルールを記述して特定のパターンをターゲットにすることができ、コードベースにスキャンを適応させる大きな力を与えます。しかし、Semgrepの狭い焦点(コードのみ)は、デフォルトではオープンソースパッケージの脆弱性、コンテナ、またはインフラストラクチャの問題をカバーしないことを意味するため、セキュリティパズルのごく一部しか解決しません。
機能ごとの比較
セキュリティスキャン機能
Snykのカバレッジ: Snykは、統合された広範なスキャン機能スイートを提供します。特にSCA(オープンソースの依存関係スキャン)において最も強力で、脆弱性データベースを使用してアプリケーション内のリスクのあるライブラリを特定します。Snykはまた、コンテナイメージとIaC(Infrastructure as Code)設定を既知の問題についてスキャンし、スタック全体を保護することを目指します。さらに、Snyk CodeはコードのSAST分析を提供しますが、これはSnykにとって新しい分野であり、その中核的な強みではありません。実際には、Snykは既知の脆弱性(CVEを持つ古いライブラリなど)を検出し、開発者が早期にそれらを修正するのを支援することで最もよく知られています。
Semgrepのカバー範囲: 対照的に、Semgrepは以下に特化しています 静的コード解析。何百ものコミュニティ作成ルール(およびカスタムルールを作成するオプション)を使用して、自身のコード内のコーディング上の欠陥、安全でないパターン、論理バグを検出するのに優れています。オープンソースパッケージのCVEの組み込みデータベースや、コンテナ/IaCのスキャン機能は標準では備わっていません。(Semgrepには「Semgrep Supply Chain」や「Semgrep Secrets」のような別のアドオンがありますが、それらはエコシステム内の異なるツールです。)主なユースケースは、アプリケーションコード自体における問題の発見です。例:安全でない使用 eval または入力サニタイズの欠如など、サードパーティコンポーネントの脆弱性ではなく、コード内の問題に焦点を当てています。これにより、SemgrepはSnykの依存関係スキャナーが見落とす可能性のあるセキュリティバグを発見できますが、 Semgrepはコード外のあらゆるものを見落とします (脆弱なライブラリバージョンや誤設定されたDockerイメージなど)。
主な違い: Snykはコード、依存関係、コンテナ、設定といったより広範なコンポーネント中心のアプローチを取るのに対し、Semgrepはより深いコード中心のアプローチを取ります。既知の脆弱性を持つオープンソースパッケージをスキャンするツールが必要な場合はSnykが適しています。チームが記述するカスタムコードについてより懸念がある場合は、Semgrepの静的解析がより直接的です。どちらのツールもギャップを残します。Snykの静的コード解析はSemgrepほど徹底的ではなく、Semgrep単独ではサプライチェーンの脆弱性に対するカバレッジを提供しません。技術リーダーは、両方の側面をカバーするために、複数のツールまたは統合プラットフォーム(Aikidoなど)を使用することがよくあります。
インテグレーションとDevOpsワークフロー
Snyk連携: Snykの最大のセールスポイントの1つは、開発者の既存のワークフローにうまく適合することです。人気のIDE向けプラグイン(これにより開発者はコーディング中に即座にアラートを受け取ります)、GitHub/GitLab/Bitbucketとのネイティブ統合、およびセキュリティ問題でビルドを失敗させることができるCI/CDパイプラインフックを提供します。Snykのクラウドサービスはリポジトリを監視し、プルリクエストを開いたり、新しいコードをプッシュしたりするたびに、SnykはGitプロバイダーのUIで問題をスキャンして報告できます。開発者はSnykが作業中の場所で直接結果を表示することを高く評価していますが、欠点としては、Snykが詳細のためにユーザーをウェブダッシュボードに誘導することが多く、コンテキストスイッチングを引き起こすことです。
特筆すべきは、SnykがマネージドSaaSプラットフォームであることです。つまり、コード(または依存関係マニフェスト)は分析のために彼らのクラウドにアップロードされます。これによりセットアップは容易になりますが(維持するサーバーがないため)、一部の企業はソースコードを外部に送信することに抵抗があり、Snykのオンプレミスオプションの欠如は、高度に規制された環境では障害となる可能性があります。また、Snykは主にクラウドリポジトリをサポートしており(Snyk SCM統合を使用する場合)、リポジトリ名の変更などが接続を破損することさえあります。全体として、すでにクラウドベースで一般的な開発ツールを使用している場合、Snykの統合は簡単です。DevSecOpsを実践するチームにとっては「プラグアンドプレイ」ソリューションですが、Snykのエコシステム内で作業することになるという注意点があります。
Semgrep連携: Semgrepのアプローチは、より柔軟で開発者主導です。オープンソースであるため、Semgrep CLIをローカルまたはCIで最小限の手間で実行できます。サービスに登録する必要もありません。これにより、Semgrepスキャンをどこにでも統合できます。例えば、プリコミットフック、GitHub Actionsワークフロー、Jenkinsパイプラインなどです。多くのチームは、公式のSemgrep GitHub ActionまたはCI/CD連携を使用して、すべてのプルリクエストにSemgrepチェックを追加し、コードレビューに直接コメントを残しています。このインラインフィードバック(PRのコメントとして問題を確認できること)により、開発者は別のアプリケーションにコンテキストを切り替えることなく、コードの問題を簡単に修正できます。
Semgrepには、結果を集約し、UIとチームコラボレーション機能を提供するオプションのSaaSプラットフォーム(Semgrep App)もあります。これはSnykのインターフェースに似ていますが、オプションです。重要な点として、必要に応じてSemgrepを完全にオフラインで実行でき、これは厳格なコードプライバシー要件を持つチームにとって魅力的です。Semgrepを統合するための学習曲線は、基本的な使用では低いです(CLIは簡単です)が、環境に合わせて調整するには、適切なルールを記述または選択する必要がある場合があります。これは「精度」のセクションで説明する追加の手順です。プラットフォームの依存関係に関して、Semgrepはツールに依存しません。どのGitシステムやCIを使用しているかに関係なく、特定のレポホスティングを強制しません(GitHub専用ソリューションとは異なります)。
この柔軟性により、Semgrepは多様なワークフローに適していますが、Snykの「クリック&ゴー」統合と比較すると、より多くの手動チューニングが必要です。
精度とパフォーマンス
誤検知とノイズ: 精度はあらゆるセキュリティツールにとって重要な要素です。誤検知が多すぎると、開発者はツールを無視し始めます。SnykとSemgrepはどちらもこの点で批判に直面していますが、その内容は異なります。SnykのSAST(コード)スキャンは、特定の言語において高い誤検知率で知られています。開発者は、実際には脆弱性ではない検出結果に圧倒されることが多く、これがツールへの信頼を損なう可能性があります。その理由の1つは、Snykのルールがほとんど汎用的でプロプライエタリであるため、ユーザーがそれらを調整するための可視性や制御が限られていることです。
Snykが何かをフラグ付けした場合、それを無視するかパッチを適用することはできますが、ルールロジックを簡単に調整することはできません。この「ブラックボックス」アプローチは、セキュリティチームが問題ではないと分かっているのに繰り返しフラグ付けされることに不満を感じさせることがあります。一方、Semgrepもデフォルトでノイズの多い結果を生成する可能性があります。パターンルールに依存しているため、調整されていないSemgrepの実行では、使用するルールセットによっては、軽微なスタイル問題や誤検知を含む多くの潜在的な問題がフラグ付けされることがあります。実際、Semgrepを効果的に使用するには、ノイズを減らすためにルールをキュレーションする必要があることが多く、広範なルールセットから始めて、関連性のないルールやノイズが多すぎるルールをオフにするという方法が考えられます。
利点として、その制御が可能である点が挙げられます。Semgrepはルールレベルの可視性を提供し、特定のルールを変更または抑制する機能があるため、時間とともにチームは誤検知を大幅に削減できます。対照的に、Snykは組み込みルールを微調整できないため、比較すると融通の利かないツールのように感じられるかもしれません。
見落としと盲点: 精度は誤検知だけでなく、各ツールが見逃すものにも関係します。Snykは多くの検出結果を既知の脆弱性データに依存しているため、CVEや既知のシグネチャを持たないカスタムコードの問題を見逃す可能性があります。Snyk Code(そのSAST)はそれらを見つけようとしますが、前述のように、これは新しいプレイヤーであり、Semgrepが適切に記述されたルールで捕捉できるような複雑な論理バグを検出できない可能性があります。
対照的に、Semgrepは特定の依存関係が脆弱であることを認識しない可能性があります(特定のバージョン文字列や使用パターンを検出するルールを作成しない限り)。そのため、「このライブラリを更新してください。既知のRCE脆弱性があります。」といった問題を完全に見逃す可能性があります。各ツールには盲点があります。Snykはコード内の特定のデータフローや品質の問題を見落とす可能性があり、Semgrepは設計上、脆弱なライブラリのバージョンや設定の問題を見落とす可能性があります。
速度とパフォーマンス: どちらのツールも比較的高速でCIフレンドリーに設計されていますが、そのパフォーマンスプロファイルは異なります。Snykのスキャン、特に依存関係のスキャンは通常高速です(Snyk Open Sourceのスキャンは数秒で完了する場合があります)。Snyk Codeの分析はクラウドベースであり、中規模のコードベースでも1分未満で結果を返すことができます。Semgrepはローカル(またはCIコンテナ内)で実行され、その徹底性を考慮すると非常に軽量です。約5万行のコードベースでも1〜2分でスキャンできる場合があります。コミュニティテストでは、Semgrepは純粋なコードスキャンにおいてSnyk Codeよりもわずかに遅い(例:中規模リポジトリで90秒対45秒)ことが示されましたが、ほとんどの場合、CIには十分な速さです。
どちらも増分的に(変更されたコードのみをスキャンして)実行でき、プルリクエストのフィードバックを高速化します。Snykのパフォーマンス上の利点は、一部クラウドリソースが作業を行うことに由来する一方、Semgrepの速度は、より重いエンタープライズSASTツールのように深いプロシージャ間分析を行わない軽量なエンジンに由来することに注目する価値があります。どちらのツールも適切に設定されていればビルド時間に大きな影響を与えず、両方ともテストと並行して実行することをサポートしています。チームがリアルタイムのフィードバックを重視する場合、SnykのIDEプラグインは入力と同時に即座の結果を提供するかもしれませんが、Semgrepのモデルは通常、保存時またはコミット時に実行されます(IDE拡張機能もありますが、それほど有名ではありません)。
要約すると、どちらのツールも実用上十分な速さですが、Semgrepの誤検知に悩まされないようチューニングに時間を費やす準備が必要です。また、Snykが開発者が選別しなければならない多数の問題を時折検出する可能性があることに留意してください。
カバレッジとスコープ
言語とフレームワーク: SnykとSemgrepはどちらも多言語サポートを謳っていますが、その網羅性は異なります。Snykは依存関係スキャンにおいて多くの言語をサポートしています(基本的に、JavaScriptのnpmからPythonのpip、JavaのMavenなど、パッケージマネージャーを持つあらゆる言語)。そのSAST(Snyk Code)は現在、Java、JavaScript/TypeScript、Python、C#、Ruby、PHPなどの主要言語とその他いくつかの言語をサポートしています。しかし、ユーザーはSnykのルールカバレッジが言語によって異なり、一部のエコシステムサポートはまだ成熟段階にあると指摘しています。
Snykが使用しているフレームワークを深くカバーしているかを確認する必要があります(例えば、SpringやExpressの一般的なパターンは処理できるかもしれませんが、よりニッチな言語やフレームワークではカバー範囲が弱い可能性があります)。Semgrepは、パターンスキャンに対応する幅広い言語をサポートしています。一般的なもの(JS/TS、Python、Java、C、Go、Rubyなど)から、Terraformの設定やKotlinのようなニッチなものまで対応しています。Semgrepのルールはコミュニティ主導であるため、言語のカバー範囲はルールの利用可能性に依存することがよくあります。利点として、Semgrepが新しい言語をネイティブでサポートしていない場合でも、チームが迅速に追加することが多く(または、限られた構文でカスタムパターンを作成することも可能です)。
ほとんどのモダンなスタックにおいて、SnykとSemgrepはどちらも言語をサポートしますが、Snykはルールの進化を待たないと、すべてのフレームワーク固有の問題を検出できない可能性があります。また、Semgrepはパターンベースであるため、最先端のフレームワークに対しては、ルールを見つけるか作成する必要があるかもしれません。
課題の種類: カバーされるセキュリティ課題の種類に関して、Snykは既知の脆弱性に対して非常に広範であり、コードの欠陥だけでなく、設定の問題(安全でないDockerベースイメージや誤設定されたAWS Terraformスクリプトなど)やコード内のシークレット漏洩もカバーします。SAST、SCA、コンテナスキャン、IaCスキャン、さらにはオープンソースのライセンスコンプライアンスなど、多くのカテゴリに対応するワンストップショップです。しかし、その広範さは焦点を希薄にする可能性があります。真に複雑なコード脆弱性パターンに対しては、Snyk Codeにはルールがない場合でも、カスタムSemgrepルールで捕捉できる可能性があります。Semgrepの検出機能は、パターンとしてコード化できるあらゆるものに及びます。
標準で、OWASP Top 10のWebアプリリスク、ハードコードされた認証情報、安全でない暗号化の使用などに対するルールが付属しています。しかし、特筆すべきは、SemgrepはCVEデータベースやコンテナベンチマークについて本質的に認識していないことです。これらに対するチェックはすべてルールとしてエンコードする必要があります。実際には、Semgrepのコミュニティは、既知の脆弱な依存関係パターン(特定のライブラリバージョンで脆弱なAPIの使用など)に対するルールを作成していますが、これは専用のSCAツールの代わりにはなりません。技術リーダーがコードからクラウドまで、SDLC(ソフトウェア開発ライフサイクル)全体にわたるカバレッジを必要とする場合、SnykもSemgrepも単独では不十分です。Snykは動的/ランタイムの側面や一部の深いコードロジックを見落とし、Semgrepは環境および依存関係のリスクを見落とします。
これは、統合プラットフォームや複数のツールが役立つ点です。例えば、Aikido SecurityはSASTとSCAの両方を1つでカバーし、これらのギャップを回避し、SnykやSemgrepを単独で使用するよりも広範なカバレッジを提供します。
顕著なギャップ: スコープの制限をまとめると、Semgrepの焦点は狭く、支援なしではシークレット、クラウド設定、コンテナなどをスキャンしません。Snykの焦点は広範ですが、コード分析では浅いです。多くの依存関係や設定の問題を検出する一方で、一部のカスタムコードの脆弱性を見落としたり、表面的な洞察しか提供しない可能性があります。また、Snykにはいくつかの技術的な制限があります。例えば、コード分析で非常に大きなファイル(1MB超)をスキャンせず、黙ってスキップするため、リポジトリに巨大な自動生成コードファイルやデータファイルがある場合、見過ごされたリスクが残る可能性があります。Semgrepには通常そのようなファイルサイズ制限はなく、スキャン対象を制御できます。本質的に、各ツールは他方が省略する部分をカバーします。一方はオープンソースと環境スキャンを行い、もう一方はコードパターン分析を行います。それらのカバレッジを重複させるには、統合の労力が必要か、これらのスキャンを統合する代替手段を使用する必要があります。
開発者エクスペリエンス
使いやすさ: 開発者の視点から見ると、Snykは非常にユーザーフレンドリーで、使い始めやすいです。サインアップし、リポジトリを接続するかCLIコマンドを実行するだけで、修正方法の参照情報とともに結果が返されます。UIは洗練されており、検出結果は、CVEの詳細や修正例などの追加情報にリンクしていることが多く、これは便利です。開発者は、特にオープンソースの脆弱性に対して、ガイド付きの修正を受けられます。Snykは、依存関係のバージョンを上げるためのプルリクエストを自動的に開くことさえでき、これは多忙なチームにとって気の利いた機能です。しかし、開発者からは、Snykの使用が“脆弱性モグラ叩き”になるという不満の声が上がっています。1つの問題を修正すると、次のスキャンでさらに多くの問題が検出され、時にはコンテキスト不足のために実際には問題ではない問題が再報告されることもあります。また、Snykの詳細情報は彼らのプラットフォーム上にあるため、開発者は問題をトリアージするために、コード環境を離れてSnykのポータルにログインする必要があります。このコンテキスト切り替えは導入を妨げる可能性があり、コーディングの一部というよりも外部プロセスのように感じられます。
SemgrepのデベロッパーUX: Semgrepは、開発者エクスペリエンスに対してより統合されたアプローチを採用しています。プルリクエストにコメントするように設定すると、開発者はコードレビュー内で直接セキュリティフィードバックを受け取ることができます。これにより、即時性が高まり、修正ワークフローを開発ワークフローと並行して進めることができます。開発者は、別のダッシュボードに移動することなく、PR内で直接検出結果について議論し、コードを調整し、修正をプッシュできます。さらに、Semgrepの検出結果は、ルールにカスタムメッセージを含めることができるため、多くの場合、非常に分かりやすいものです(例:「この行はSQLインジェクションのリスクがあるようです。パラメータ化されたクエリの使用を検討してください」)。
この明確さとコンテキスト内でのアプローチは、開発者の防御的な姿勢を和らげる傾向があります。外部監査というよりも、コードレビューのフィードバックのように感じられるためです。その反面、Semgrepでは、Snykを使用する場合よりも、開発者がルールのチューニングや誤検知の処理に深く関与する必要があるかもしれません。カスタムSemgrepルールを作成するための学習曲線は急ではありませんが(特にコーディングに慣れているエンジニアにとっては)、追加の作業となります。また、一部の開発者は、Semgrepの生の出力(PR統合を使用しない場合)が、設定するまでは少しノイズが多いと感じるかもしれません。UIに関しては、Semgrepアプリ(使用する場合)は改善されていますが、プロジェクト全体の問題を追跡するためのSnykのインターフェースほど成熟しておらず、包括的ではありません。デザイン上は最小限であり、実用的な雰囲気に合っていますが、大規模なチームにとっては、ワークフロートラッキング、アサイン、履歴メトリクスなどの機能はまだ十分に構築されていません。
技術リーダーは、Snykがより「エンタープライズ」向けのレポート機能(ダッシュボード、コンプライアンスレポートなど)を提供している点に注目するかもしれません。一方、Semgrepは開発者へのタイムリーなアラート配信に重点を置いています。これは哲学的な違いです。Snykは(管理者向けのダッシュボードを備えた)ワンストッププラットフォームを目指しているのに対し、Semgrepは、派手なダッシュボードよりも開発者のワークフロー統合と柔軟性を優先しています。
自動化と修正: どちらのツールも、問題の修正を支援する方法を進化させています。Snykは依存関係の問題に対して自動修正プルリクエストを提供し、コードの問題に対しては修正例(多くの場合、ナレッジベースからのスニペット)を表示します。Semgrepは導入しました Semgrep Autofix/AssistantこれはAIを使用して、特定の検出結果に対して実際のコード変更を提案します。例えば、Semgrepが危険な使用法を検出した場合、 evalアシスタントは、それを置き換えるためのより安全なコードスニペットを提案するかもしれません。初期フィードバックでは、これは開発者の時間を節約できると示されていますが、完璧ではありません。Snykのアプローチはより伝統的で、コードを自動的に変更するわけではありません(依存関係を除く)が、ガイダンスを提供します。
開発者の好みによっては、Semgrepの自動修正の試みを好むかもしれませんし、Snykの明示的な参照を好むかもしれません。誤検知の処理: 開発者エクスペリエンスに関するもう一点:検出結果が実際には問題ではない場合、どれだけ簡単に無視できるでしょうか?Snykでは、項目を無視としてマークできます(有効期限オプション付き)が、ルールがわずかに異なるコードでトリガーされた場合、再び表示されます。
Semgrepでは、ルールを完全に変更または無効化できるため、より永続的な解決策が得られます(ただし、実際の問題を無効にしないよう注意が必要です)。同じ誤検知が繰り返し表示されるのを嫌う開発者は、Semgrepがフィードバックから学習する点(検出結果を誤検知としてフラグ付けすると、そのパターンをフラグ付けしないようにルールを調整できる)を高く評価するかもしれません。Snykの場合、開発者はツールの癖に縛られ、特定の問題ではないものを受け入れるか、毎回手動でフィルタリングしなければならないと感じることがあります。
価格とメンテナンス
Snykの料金: Snykは、段階的な料金モデルを持つ商用SaaSです。小規模またはオープンソースプロジェクト向けに無料ティアを提供していますが(テスト数に一部制限あり)、チームまたはエンタープライズレベルでの本格的な利用には有料プランが必要です。Snykは通常、開発者シートごとに課金され(一部の製品ではプロジェクトごとに課金される場合もあります)、エンジニアリングチームを拡大するにつれて高額になる可能性があります。組織は、Snykを数十のリポジトリや開発者に統合するにつれて費用が急増することに気づくことが多く、コストを抑えるために重要なリポジトリのみを選択的にスキャンするようになることもあります。Snykのエンタープライズプランには、カスタムSLAレポートやオンプレミスサポート(稀なケース)などの機能が追加されますが、これらはプレミアム料金がかかります。要するに、Snykはこの分野で最も高価なツールの1つとなる可能性があり、その予算編成はセキュリティリーダーにとって考慮すべき点です。
Semgrepの料金: Semgrepのコアはオープンソースであり、無料で利用できます。これは、CLIまたはCI経由で無制限のスキャンを無料で実行できることを意味し、予算を重視するチームにとっては大きな利点です。Semgrepを提供する企業は、マネージドクラウドアプリ、追加のルールライブラリ、およびサポートを含む有料のエンタープライズプラン(Semgrep Team/Enterprise)を提供しています。これらのプランも通常、シートごと(つまり、開発者ごとまたはプロジェクトシートごと)に料金が設定されています。それでも、無料版を自由に利用できるため、チームはSemgrep Community Editionから始めることが多く、集中管理プラットフォームの利便性や高度な機能が必要な場合にのみ有料版を検討します。
しかし、Semgrepではメンテナンスがコストとなります。それはルールとツールの管理にかかる運用上のオーバーヘッドです。サブスクリプションの代わりに、ルールを最新の状態に保ち、検出結果をトリアージするためにエンジニアの時間を費やします。数個のリポジトリを持つ小規模チームにとって、このコストは無視できる程度です。しかし、大規模な組織では、多数のカスタムSemgrepルールと抑制を維持することがかなりの労力となる可能性があります。一部の企業は、コミュニティのルールパックを使用し、貢献することでこれを軽減し、事実上、一部のメンテナンスをコミュニティにアウトソーシングしています。それでも、大規模に微調整するためのエンジニアリング時間を考慮すると、Semgrepは「無料」ではないという点を考慮に入れることが重要です。
メンテナンスとインフラストラクチャ: Snykの場合、インフラストラクチャのメンテナンスは最小限です。クラウドSaaSであるため、サーバーを維持する必要はありません(Snykのオンプレミスアプライアンスを選択しない限り。これは一般的ではなく、追加費用が発生する可能性があります)。統合の管理(各リポジトリがリンクされ、各パイプラインにSnykステップがあることなど)と、CLIを使用する場合はその更新を維持する必要があります。Snykは脆弱性データベースの更新とルールの改善を自社側で行います(これらの更新によって、一夜にして新しい検出結果が導入されることもあります)。セルフホスト型Semgrepの場合、CLIを最新の状態に保つ必要があります(これはCIでのpip installやバイナリダウンロードと同じくらい簡単です)。
Semgrep Appをご利用の場合、SaaSとして提供され、ベンダーがメンテナンスを行います。ただし、ご希望に応じて内部デプロイメントをホストすることも可能です(これにはサーバーといくつかのセットアップが必要です)。一般的に、Semgrepのメンテナンスはツール自体よりもコンテンツ(ルール)に関するものです。
料金体系の透明性: SnykとSemgrepのエンタープライズ向け料金は、どちらもやや複雑になる場合があることに注意が必要です。Snykはカスタムのエンタープライズ契約を交渉することが多く、Semgrepの有料ティアの料金は公開されておらず、通常、見積もりには問い合わせが必要です。ここでAikido Securityが差別化を図ります。Aikido は、プロジェクトや開発者を追加してもペナルティがない、よりシンプルでフラットな料金モデルを提供しています。SnykやSemgrepの有料プランのシートごとのコストと比較して、より予測可能で、規模が大きくなっても手頃な価格となる傾向があります。
各ツールの長所と短所

Snykの長所:
- 幅広いセキュリティカバレッジ: コード、オープンソースの依存関係、コンテナ、設定ファイルなどを1つのプラットフォームでスキャンし、広範なセキュリティ網を提供します。
- 開発者に優しい統合: リポジトリ、CI/CD、IDEに簡単に組み込むことができ、開発ワークフローにおける自動スキャンと迅速なフィードバックを実現します。
- 依存関係に対する実用的な修正: 明確なアップグレードガイダンスを提供し、脆弱なライブラリを修正するための自動プルリクエストまで行い、SCAの問題に対する修正を簡素化します。
- 直感的なUI: 脆弱性の詳細、優先順位付けのヒント、および詳細情報へのリンクを備えた洗練されたダッシュボードは、問題の修正方法を学ぶ開発者にとって役立ちます。
Snykの短所:
- SASTにおける高い誤検知: 静的コード分析は、多くの誤検知を頻繁に報告し、開発者のアラート疲れを引き起こします。
- 浅いコード分析: 既知のCVE検出には強いものの、カスタムコード内の複雑なバグの発見には弱いです(一部のSASTツールのような高度なデータフロー分析やランタイム分析はありません)。
- 大規模でのコスト: 大規模なチームの場合、開発者ごとの料金は高額になる可能性があり、高度な機能はエンタープライズプランでのみ利用可能です。
- カスタマイズの制限: 検出ロジックを調整できないクローズドソースのルールであり、誤検知が発生した場合、ベンダーのアップデートを待つか、扱いにくい無視メカニズムを使用する必要があります。
- 統合における潜在的な摩擦: クラウドサービスへのデータアップロードが必要であり(一部の組織では許可できない場合があります)、また、プラットフォームは、明確な通知なしに大きなファイルや特定のファイルのスキャンをスキップする場合があります。

Semgrepの利点:
- 強力な静的解析: 軽量なルールでコードの脆弱性やアンチパターンを検出するのに優れており、多くの言語とフレームワークに対応しています。
- 高いカスタマイズ性: セキュリティエンジニアは、自身のコードベースに関連するパターンをターゲットとするカスタムルールをYAMLで記述できます。この柔軟性により、一般的なツールでは見逃してしまうような、アプリケーション固有の問題を発見できます。
- 高速かつ軽量: CIパイプラインでビルド時間への影響を最小限に抑えながら高速に実行され、運用に重いインフラやクラウドのリソースを必要としません。
- 開発者中心のワークフロー: プルリクエストや開発者ツールに統合され、開発者が有用だと感じる即時かつ文脈に沿ったフィードバックを提供します(外部のスキャナーというよりも、コードレビューの一部のように感じられます)。
- オープンソースと透明性: スキャンエンジンと多くのルールセットは公開されており、チームはどのようなチェックが実行されているかを完全に可視化し、それらを調整または拡張することができます。ブラックボックスはありません。
Semgrepのデメリット:
- 狭い焦点: コード(SAST)のみをカバーします。オープンソースの依存関係の脆弱性、シークレット、コンテナ、またはIaCの組み込みスキャン機能がないため、セキュリティスペクトルの限られた範囲しか対応していません。完全なカバレッジのためには、チームは追加のツールが必要になります。
- チューニングなしではノイズが多い: デフォルトのルールセットは、誤検知を含む多くの検出結果を生成する可能性があり、無関係なルールを除外し、ノイズを減らすために事前のチューニングが必要です。このチューニングにはセキュリティの専門知識と、コードの進化に応じた継続的な調整が求められます。
- メンテナンスのオーバーヘッド: 大規模なカスタムルールライブラリを管理し、コードベースと脅威の状況の変化に合わせて最新の状態に保つことは、継続的な取り組みです。エンタープライズ規模では、専任のAppSecエンジニアなしでは負担となる可能性があります。
- 限られたコンテキストと優先順位付け: 検出結果は、より広範なコンテキスト(例:脆弱なコードが実際に到達可能であるか、ランタイムでエクスプロイト可能であるか)なしにパターンマッチングに基づいています。これにより、リスクコンテキストを組み込むツールとは異なり、どの問題が本当に重要であるかについてのガイダンスがないまま、長い問題リストが発生する可能性があります。
- 少ないエンタープライズ機能: 大規模な組織が求める可能性のあるガバナンス、レポート、コンプライアンス機能(例:監査ログ、ロールベースアクセス、標準装備のコンプライアンスチェックなど)の一部が不足しています。Semgrepはこの点で改善していますが、その主要な焦点は、監査人を満足させることよりも開発者を支援することにあります。
Aikido Security: より良い代替策
現代のセキュリティチームは、SnykとSemgrepの両方の強みを、手間なく必要とすることがよくあります。Aikido Securityは、コードスキャンと依存関係スキャンを1つの開発者に優しいプラットフォームに統合したソリューションとして構築されました。SASTとSCAをまとめてカバーするため、複数のツールを使い分ける必要がありません。
複数のスキャンタイプを1か所にまとめることで、Aikidoは脆弱性を文脈化し、誤検知を除外できます。これによりノイズを最大95%削減します。誤検知が少ないほど、開発者は検出結果を信頼します。統合はシームレスです。AikidoはSnykのようにリポジトリやパイプラインに連携するだけでなく、Semgrepのようにインラインで結果を提供し、摩擦を最小限に抑えます。主な利点はスマートな自動化、例えばAIを活用した修正と優先順位付けから生まれ、チームの時間を節約します。
従来のベンダーとは異なり、Aikidoは実用的で透明性を保ちます。料金はフラットで予測可能であり、SnykやSemgrepが規模に応じて高価になる原因となる高額なシートごとのコストを回避します。要するに、Aikidoは両方の世界を1つのプラットフォームに統合し、はるかに少ないノイズと複雑さで、通常のツール疲れなしに効果的なセキュリティを求めるチームにとってより良い選択肢となります。


