Static Application Security Testing (SAST)は、実行中のアプリではなくソースコードをスキャンし、安全でないコーディングパターンが本番環境に到達する前に発見します。コード作成中という修正コストが最も低い段階でエラーを検出するため、開発ワークフローに追加できる最も早期かつ効果的なセキュリティツールの一つです。
SASTが実際に何をするか
SASTはソースファイルを分析し、SQLクエリで使用されるサニタイズされていないユーザー入力、不適切な暗号化、安全でない認証フローなど、脆弱性を示すパターンを探します。コードを静的に(実行せずに)検査するため、SASTはSDLCの早期に安全でないコーディングプラクティスを検出するのに優れています。
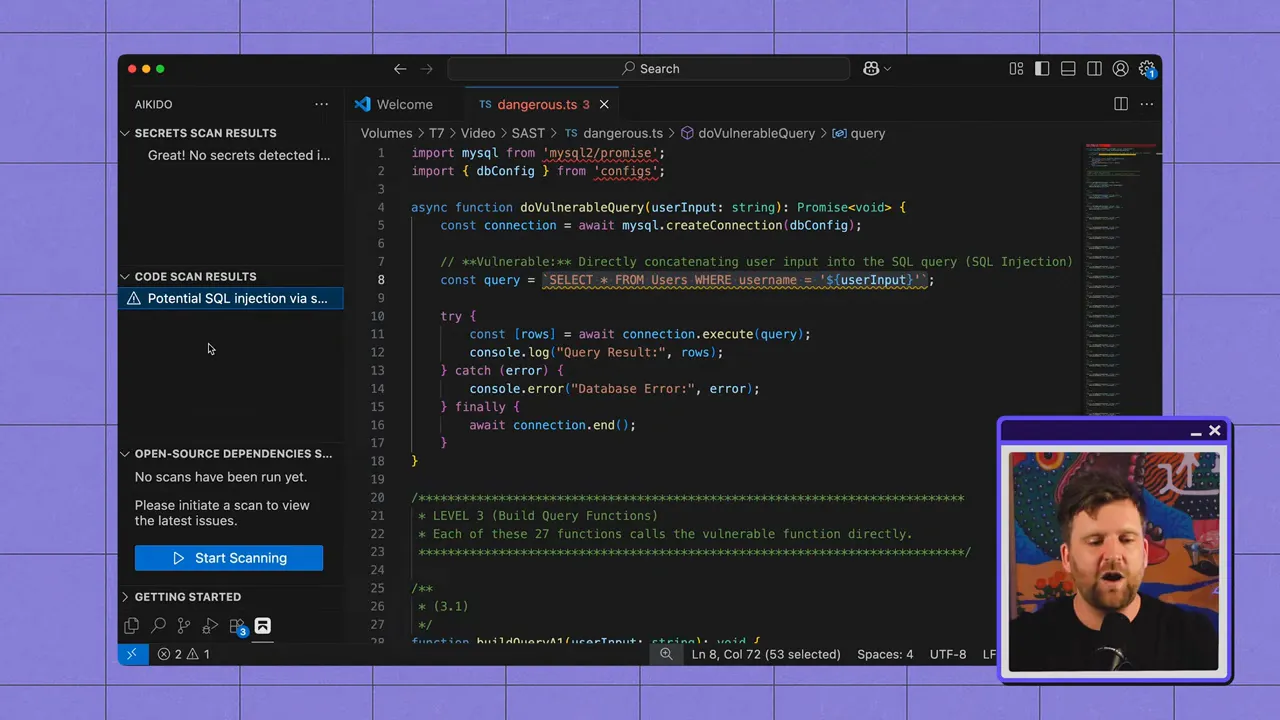
SASTが真価を発揮する場所
- 早期検出: IDEまたはCIパイプラインで実行され、ステージングや本番環境に移行する前に誤りを検出します。
- ルールベースのカバレッジ: 既知の安全でないパターン(例:SQLインジェクションのソース/シンク)は、適切に記述されたルールによって確実に検出できます。
- 開発者に優しいフィードバック: 統合により、コンテキスト内で問題を表面化させることができるため、エンジニアはすぐにそれらを修正できます。
その制限
- 限られたランタイムコンテキスト: SASTは、コードパスが本番環境で到達可能かどうか、またはランタイム構成と依存関係がリスクにどのように影響するかを容易に判断できません。
- ロジックの欠陥への対応が不十分: ビジネスロジックの脆弱性や複雑な認証の問題は、純粋な静的ルールでは検出が困難です。
- 依存関係と環境の盲点: ランタイムまたは外部パッケージを介して導入される脆弱性は、静的解析では見落とされがちです。
SASTが脆弱性を検出する方法:ルールとAIの比較
従来のSASTツールは主にルールベースであり、エンジンがコードを解析し、既知の安全でないパターンに一致する何千ものルールを適用します。このアプローチは、パターンが十分に理解されているため、多くの種類の欠陥に対して効率的かつ正確です。
「静的コードに関しては、コードを脆弱にするパターンを私たちは真に理解しています。」
一部のベンダーはAI駆動型の検出を推進していますが、生のLLMスキャンはノイズが多く、計算コストが高い傾向があります。有名な例えが当てはまります。フェラーリで芝生を刈るようなものです。代わりに、これまでのAIの最も効果的な使い方は、スキャンそのものではなく、プロジェクト全体のコンテキストを追加してトリアージと修正提案を改善することです。
実践におけるオープンソースSAST: OpenGrep(Semgrepのフォーク)
オープンソースのSASTツールは、スキャンエンジンとルールセットが分離されているため、優れた出発点となります。エンジンはパースとマッチングを実行し、多くの場合コミュニティによって維持されているルールは、「悪いもの」がどのようなものかを定義します。
エンジンとルールを組み合わせたモデルを使用すると、次のことが可能になります。
- コードベースのルールを検査し、カスタマイズします。
- 商用ルールセットでは見逃される独自のパターンに対して、プロジェクト固有のルールを記述してください。
- チームや他のユーザーが恩恵を受けられるよう、有用なカスタムルールをコミュニティと共有しましょう。
なぜ誤検知が評判の問題となったのか
ルールベースのSASTは、しばしば広範囲にわたる検出を行います。これはリコール率を高め(より多くの潜在的な問題を発見できる)、良いことですが、同時に多くのノイズも引き込みます。フラグが立てられた問題の多くは、本番環境では到達不能であったり、特定のプロジェクトコンテキストでは安全であったりするため、チームは重要でないアラートの調査に時間を費やしてしまいます。
従来のSASTは、巨大な網を使った漁のようなものだと考えてみてください。魚は捕れますが、大量のゴミも一緒に捕れてしまいます。価値のあるものを見つけるには、そのすべてを選別する必要があります。
AIがSASTに実際に役立つ点:Auto-TriageとAuto-Fix
ルールベースのスキャンを置き換えるのではなく、最新のSASTツールは、静的ルールと、コンテキストを追加してノイズを削減するAI搭載レイヤーを組み合わせています。
- AI自動トリアージ: AIモデルはSASTの結果とプロジェクトのコンテキストを取り込み、到達可能性と現実世界への影響を推定します。開発者が最初に修正する必要がある発見事項(本番環境に影響を与えるもの、到達可能なパス、影響の大きい問題)を優先します。
- コールツリーと到達可能性: AIはフラグが付けられた関数のコールツリーを構築し、入力がどこから発生し、データがリポジトリをどのように流れるかを示すことで、問題が悪用可能であるかどうかを判断しやすくします。
- 自動修正の提案: AIは、簡潔で実行可能なコード修正(例:文字列連結SQLの代わりにパラメータ化クエリ)を提案でき、これによりIDE内での修復が加速されます。

開発ワークフローでSASTを実行する場所
価値を最大化するには、SDLCの複数の段階でSASTを実行します。
- IDE内: IDEプラグインは、開発者がコードを入力する際に問題を検出し、即座の修正と学習を可能にします。
- リモートリポジトリ内: リポジトリのスキャンは、出荷されるものの単一の信頼できる情報源を提供します。これは、IDEスキャンが見落とされたり、誤って設定された場合に不可欠です。
- CI/CDパイプラインにおいて: ビルド中の自動スキャンはポリシーゲートを強制し、安全でないコードがステージング環境や本番環境に進むのを防ぎます。

チーム向けの実用的な推奨事項
- オープンソースから始める:コミュニティツールを使用して、SASTがコードベースで何を発見するかを学び、商用ツールを購入する前に自信をつけましょう。
- ルールのカスタマイズ: スタックに固有のパターンに対してプロジェクト固有のルールを追加し、役立つルールをコミュニティと共有できます。
- AIが役立つ場所にAIを導入する: AIを活用したトリアージを導入してノイズを削減し、自動修正で修復を加速します。しかし、今日のところは大規模な生のスキャンにLLMを頼るべきではありません。
- 3つのポイントで統合します: 開発者の即時性のためのIDE、信頼できる情報源としてのリポジトリ、強制のためのCI。
- 測定と調整: チームがスキャナーを信頼できるよう、シグナル対ノイズ比を追跡し、しきい値を調整し、ルールとトリアージモデルを反復します。
まとめ
SASTは、コードレベルの問題を早期に発見するため、セキュリティリスクを低減するための最も費用対効果の高い方法の1つです。ルールベースのエンジンは検出の主力であり続けていますが、AIは検出結果の優先順位付け、到達可能性の説明、修正案の提案を行うコンテキストレイヤーとして最も価値があることが証明されています。
まずオープンソースのSASTから小さく始めて、コードにどのような問題が存在するかを発見しましょう。ノイズや規模が問題になった場合は、AIを活用したトリアージと自動修正を追加して、開発者にとってより速く、摩擦の少ない真の脆弱性修正を実現します。今すぐAikido Securityをお試しください!


